Model, Algorithm, Agent¶
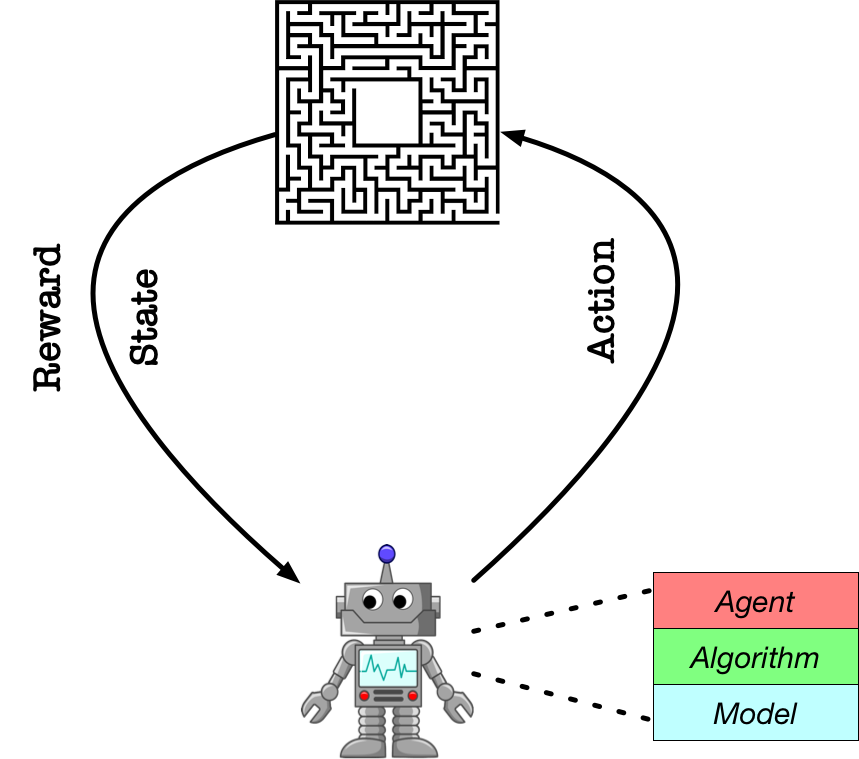
In the previous tutorial, we quickly demonstrate three basic blocks of PARL: Model, Algorithm, Agent, and use these basic blocks to construct final Cartpole Agent interacting with the environment. Now, in this tutorial, we will introduce in detail the specific positioning of each module, as well as the usage specifications.
Model¶
- Definition:
Modeldefines Forward Network, it is usually a Policy Network or a Value Function Network. The current environment status (State) is the input to the Network. - ⚠️Warning: customized
Modelhas to inheritparl.Model. - Methods that must be implemented:
forward: define computation of Forward Network according to components in__init__.
- Remarks: Implementation of Target Network is easy in PARL using
copy.deepcopy. - Examples:
import paddle
import paddle.nn as nn
import parl
import copy
class CartpoleModel(parl.Model):
def __init__(self, obs_dim, act_dim):
super(CartpoleModel, self).__init__()
hid1_size = act_dim * 10
self.fc1 = nn.Linear(obs_dim, hid1_size)
self.fc2 = nn.Linear(hid1_size, act_dim)
self.tanh = nn.Tanh()
self.softmax = nn.Softmax()
def forward(self, x):
out = self.tanh(self.fc1(x))
prob = self.softmax(self.fc2(out))
return prob
if __name__ == '__main__:
model = CartpoleModel()
target_model = copy.deepcopy(model)
Algorithm¶
- Definition:
Algorithmwill update the parameters of theModelpassed to it. In general, we define the loss function inAlgorithm. EachAlgorithmcontains at least oneModel. - ⚠️Warning: it is recommended to directly import PARL’s implementations of
Algorithms. - Methods that must be implemented:
learn: using training data (observations, rewards, actions, etc.) to update parameters inModel.predict: using current observation to predict the current action distribution or action value function.
- Examples:
model = CartpoleModel(act_dim=2)
algorithm = parl.algorithms.PolicyGradient(model, lr=1e-3)
Agent¶
- Definition:
Agentis used to interact with the environment to generate training data. The training data is then passed toAlgorithmto update the parameters ofModel. It also handles data preprocessing. - ⚠️Warning: customized
Agenthas to inheritparl.Agentand call parent class’s__init__method inside its constructor. - Methods that must be implemented:
learn: using training data (observations, rewards, actions, etc.) to update parameters inModel.predict: return a predicted action based on current observation, this function is often used for evaluation and deployment of theAgent.sample: return a sampled action based on current observation, this function is often used in training to help theAgentexplore the observation space.
- Examples:
class CartpoleAgent(parl.Agent):
def __init__(self, algorithm):
super(CartpoleAgent, self).__init__(algorithm)
def sample(self, obs):
obs = paddle.to_tensor(obs, dtype='float32')
prob = self.alg.predict(obs)
prob = prob.numpy()
act = np.random.choice(len(prob), 1, p=prob)[0]
return act
def predict(self, obs):
obs = paddle.to_tensor(obs, dtype='float32')
prob = self.alg.predict(obs)
act = int(prob.argmax())
return act
def learn(self, obs, act, reward):
act = np.expand_dims(act, axis=-1)
reward = np.expand_dims(reward, axis=-1)
obs = paddle.to_tensor(obs, dtype='float32')
act = paddle.to_tensor(act, dtype='int32')
reward = paddle.to_tensor(reward, dtype='float32')
loss = self.alg.learn(obs, act, reward)
return float(loss)
if __name__ == '__main__':
model = CartpoleModel()
alg = parl.algorithms.PolicyGradient(model, lr=1e-3)
agent = CartpoleAgent(alg, obs_dim=4, act_dim=2)