Overview¶
Easy-to-use¶
With a single
@parl.remote_class decorator, users can implement parallel
training easily, and do not have to care about stuff of multi-processes,
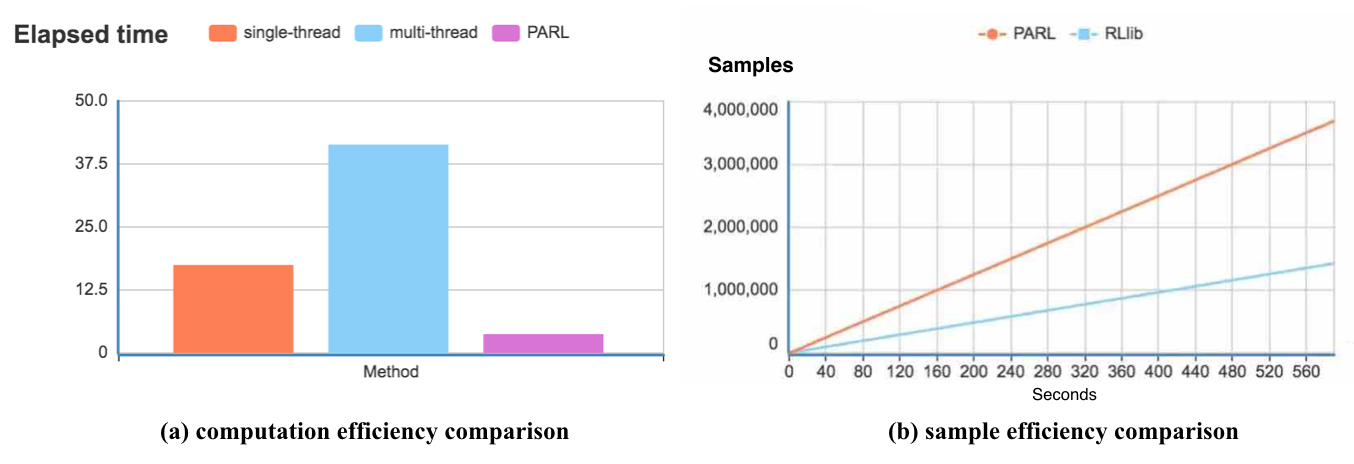
network communication.High performance¶
@parl.remote_class enable us to achieve real multi-thread computation
efficiency without modifying our codes. As shown in figure (a), python’s
original multi-thread computation performs poorly due to the limitation
of the GIL, while PARL empowers us to realize real parallel computation
efficiency.Web UI for computation resources¶
PARL provides a web monitor to watch the status of any resources connected
to the cluster. Users can view the cluster status at a WEB UI. It shows the
detailed information for each worker(e.g, memory used) and each task submitted.
Supporting various frameworks¶
PARL for distributed training is compatible with any other
frameworks, like tensorflow, pytorch and mxnet. By adding
@parl.remote_class
decorator to their codes, users can easily convert their codes to distributed
computation.Why PARL¶
High throughput¶
PARL uses a point-to-point connection for network communication in the
cluster. Unlike other framework like RLlib which replies on redis for
communication, PARL is able to achieve much higher throughput. The results
can be found in figure (b). With the same implementation in IMPALA, PARL
achieved an increase of 160% on data throughout over Ray(RLlib).
Automatic deployment¶
Unlike other parallel frameworks which fail to import modules from
external file, PARL will automatically package all related files and send
them to remote machines.